
728x90
In-context learning
1️⃣ In-context learning 이란

📌 BERT 방식
- BERT는 언어를 배우는 모델
- 처음에는 아주 많은 텍스트 데이터를 학습하면서 "언어 자체를 이해하는 모델"로 훈련된다.
- 이 과정에서 문장 속 일부 단어를 가려놓고 어떤 단어가 들어갈지 맞히는 방식(MLM)과 문장 관계를 예측하는 방식(NSP)을 사용한다.
- 이때 BERT의 모든 파리미터(가중치)가 업데이트되면서, 문맥과 의미를 이해하는 능력을 갖추게 된다.
- 서브테스크(Subtask)란?
- BERT는 기본적으로 언어를 이해하지만, 우리가 실제로 하고 싶은 일은 여러 가지이다.
- 언어와 관련된 대표적인 서브테스크(세부 과제)에는 다음과 같은 것들이 있다.
- 요약: 긴 문서를 짧게 정리하는 작업
- 번역: 한 언어를 다른 언어로 변환하는 작업
- 감정 분석: 문장에서 긍정, 부정을 판별하는 작업
- 질의응답: 질문을 주면 문서에서 답을 찾아주는 작업
- BERT를 서브테스크에 맞게 파인튜닝하기
- 프리트레이닝된 BERT는 "언어를 이해하는 능력"은 있지만, 특정한 서브테스크를 수행하는 데 최적화되지는 않았다.
- 그래서 각 서브테스크마다 별도로 데이터를 모아서 추가 학습(파인튜닝)을 진행한다.
- 예를 들어,
- 요약 데이터를 학습 → "요약을 잘하는 BERT"
- 번역 데이터로 학습 → "번역을 잘하는 BERT"
- 감정 분석 데이터 학습 → "감정 분석을 잘하는 BERT"
- 이렇게 하나의 BERT 모델을 여러 가지 언어 관련 작업에 맞춰 활용할 수 있다.
📌 In-Context Learning 방식
- In-Context Learning이란
- GPT-3 이후 등장한 접근 방식으로, 아예 파인튜닝을 생략하는 것이 핵심이다.
- 대규모 LLM(예: GPT-3, GPT-4 등)은 이미 방대한 데이터를 학습하면서 언어 자체를 이해하는 능력을 갖추고 있다.
- 따라서, 새로운 작업을 수행하려고 할 때, 굳이 파라미터를 업데이트(즉, 파인튜닝)할 필요 없이 적절한 프롬프트만 제공하면 된다.
- In-Context Learning의 접근 방식
- In-Context Learning에서는 이미 학습된 모델을 활용하면ㅁ서, 문제를 해결하기 위한 정보를 프롬프트를 통해 제공하는 방식을 사용한다.
- 예를 들어,
- 번역 작업 수행 시
- "Translate the following English sentence to French: "Hello, how are you?"
- 이렇게 직접 프롬프트를 작성하면 추가적인 모델 학습 없이도 번역이 가능하다.
- 감정 분석 수행 시
- "Classify the sentiment of this review as Positive, Negative, or Neutral: 'This product is amazing!"
- 이렇게 프롬프트를 잘 작성하면, 따로 감정 분석을 위한 모델을 학습할 필요 없이 결과를 얻을 수 있다.
- 번역 작업 수행 시
🌱 왜 In-Context Learning이라 이름 붙였을까?
1. "Context(컨텍스트)"란?
- 우리가 모델에 제공하는 입력(프롬프트) 내에서 주어진 정보를 의미.
2. "Learning(학습)"이란?
- 기존의 머신러닝에서는 "학습(Learning)"이라는 단어가 데이터를 사용해서 모델의 파라미터를 업데이트하는 과정을 의미함.
- 하지만 In-Context Learning에서는 모델이 새로운 데이터를 학습하는 과정 없이도, 프롬프트(맥락)만 보고 문제를 해결할 수 있음.
- 즉, 모델이 컨텍스트(입력된 예시)를 활용해 마치 학습한 것처럼 동작하기 때문에 Learning이라는 표현을 씀.
[결론]
주어진 맥락(Context) 안에서만 학습한 것처럼 동작한다는 의미에서 "In-Context Learning"이라 불림.
📌 BERT와 In-Context Learning의 차이점
| 구분 | BERT 파인튜닝 | In-Context Learning |
| 학습 방식 | 새로운 작업마다 추가 데이터로 학습 필요 | 기존 모델을 그대로 사용 |
| 데이터 필요 여부 | 반드시 필요한 데이터 수집 후 학습 | 별도 데이터 학습 없이 프롬프트만 작성 |
| 사용 예시 | 번역 모델을 만들려면 영어-불어 데이터를 모아 다시 학습 | "Translate this sentence to French:"라고 입력하면 바로 번역 |
| 유연성 | 특정한 작업(예: 감정 분석, 번역 등) 전용 모델이 됨 | 프롬프트만 수정하면 다양한 작업 가능 |
| 파라미터 업데이트 | 파라미터를 다시 학습(모델이 변함) | 모델 자체는 변하지 않고, 입력을 조정하는 방식 |
2️⃣ In-context learning 이란 - Zero-shot
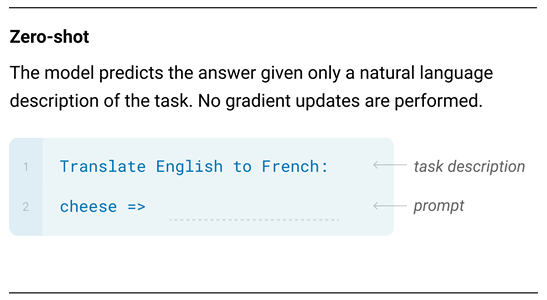
- Zero-shot은 프롬프트에 추가적인 설명 예제 없이 바로 문제를 해결하려는 세팅이다.
- 즉, "이걸 해줘!" 라고만 말하고, 별다른 설명이나 예시 없이 바로 답을 받는 것이다.
- 예제
- 프롬프트: "Translate English to French: cheese"
- 모델출력: "fromage"
- 설명이나 예시 없이도 모델이 바로 답을 예측함.
- Zero-shot의 특징
- 사용자 입장: 편리함(추가 정보 없이 바로 요청 가능)
- 모델입장: 어려움, 하지만 대규모 LLM은 충분한 데이터로 학습되어 있기 때문에 가능함.
- 파라미터 업데이트 없음 → 모델은 기존 학습된 지식만 활용
🌱 파라미터(Parameter) 란?
- 파라미터는 모델이 학습하는 동안 업데이트 되는 값들.
- 신경망에서는 가중치(Weight)와 편향(Bias) 같은 값들이 파라미터에 해당.
- 이 파라미터들이 훈련 데이터를 기반으로 조정되면서 모델이 더 정확한 예측을 할 수 있도록 학습됨.
🌱경사하강법
- 머신러닝 모델은 학습(Training)을 통해 점점 더 나은 결과를 내도록 파라미터(Parameter)를 조정함.
- 이때 경사 하강법(Gradient Descent)은 오차(실제 값과 예측 값의 차이)를 줄이기 위해 파라미터를 업데이트하는 과정을 의미함.
3️⃣ In-context learning 이란 - One-shot

- One-shot은 프롬프트에 추가적인 설명 예제 1개와 함께 문제를 해결하려는 세팅이다.
- 즉, 설명만 하는 Zero-shot과 다르게, 한 개의 예시를 추가해 모델이 더 쉽게 패턴을 이해하도록 한다.
- 예제
- 프롬프트:
- Translate English to French:
- 예시: Apple → Pomme
- 입력: "Cheese"
- 모델출력: "Fromage"
- 프롬프트:
- One-shot의 특징
- Zero-shot보다 모델이 문제를 이해하기 쉽다
- 사용자는 예제 하나만 제공하면 된다.
- 파라미터 업데이트 없음 → 모델은 기존 학습된 지식만 활용
4️⃣ In-context learning 이란 - Few-shot

- Few-shot은 프롬프트에 추가적인 설명 예제 n개와 함께 문제를 해결하려는 세팅이다.
- One-shot보다 더 많은 예제를 포함해 모델이 패턴을 더 잘 학습할 수 있도록 도움.
- 예제
- 프롬프트:
- Translate English to French:
- 예시1: Apple → Pomme
- 예시2: Dog → Chien
- 예시3: House → Maison
- 입력: Cheese
- 모델 출력: "Fromage"
- 프롬프트:
- Few-shot의 특징
- 예제 개수가 늘어날수록 모델이 더 정확하게 패턴을 학습함
- 예제가 3개면 Three-shot, 예제가 7개면 Seven-shot처럼 불림
- Zero-shot, One-shot보다 더 많은 제공 → 모델이 문제를 더 쉽게 이해
- 파라미터 업데이트 없음 → 기존 학습된 지식만 활용
5️⃣ shot 별 성능 비교
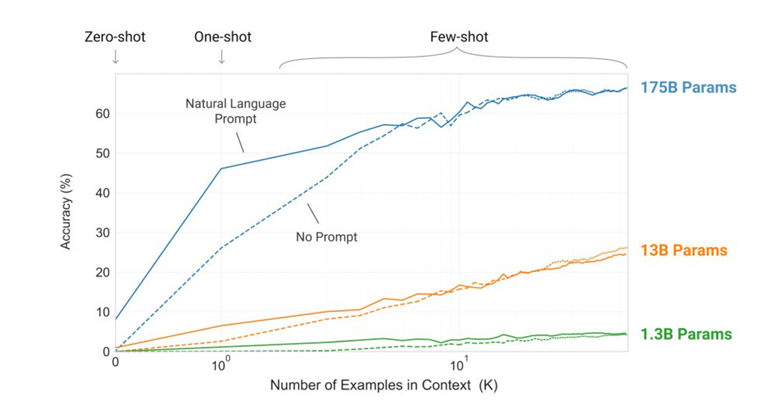
- 사용자 입장:
- Zero-shot이 가장 편리함
- Few-shot은 예제를 여러 개 넣어야 해서 조금 번거로움
- 모델 성능:
- Zero-shot이 가장 성능이 낮고, 예제 개수를 늘릴수록 성능이 향상됨.
- Few-shot이 가장 성능이 좋을 가능성이 높음
- One-shot만 해도 Zero-shot보다 큰 성능 개선이 있음 → 최소 1개 이상의 예제를 넣으면 성능 향상을 기대할 수 있음
6️⃣ In-context Learning과 Prompt Engineering
- 추가적인 Fine-Tuning 없이도 In-context Learning 만으로 원하는 결과를 얻는 것이 가능해지면서, 어떻게 프롬프트를 작성하면 LLM에게서 더 효과적으로 정보를 얻어내는 프롬프트를 작성할 수 있는지를 연구하는 프롬프트 엔지니어링(Prompt Engineering) 기법이 활발히 연구되기 시작하였다.
728x90
'AI & 딥러닝' 카테고리의 다른 글
| LLM 용어 정리 - 온도(Temperature) (0) | 2025.02.26 |
|---|---|
| LLM 용어 정리 - 창발 능력(Emergent Abilites) (0) | 2025.02.26 |
| LLM 용어 정리 - 토크나이징 (0) | 2025.02.26 |
| 기업별 대표 LLM 사용 및 비교해보기 ChatGPT, Bard, CLOVA X (0) | 2025.02.25 |
| LLM(Large Language Model)이란 (1) | 2025.02.21 |