
728x90
1️⃣ 언어 모델(Language Modelling)에서 다음 토큰의 확률 예측
- 언어 모델링(Language Modelling)에서 다음 토큰의 예측은 단어 집합(Vocabulary)에 존재하는 단어들에 대한 Softmax Regression 값이 된다.
- Softmax Regression: 언어 모델이 단어 집합(Vocabulary)에서 다음 단어를 선택할 때 확률을 계산하는 방식, 모델이 각 단어에 대한 점수를 계산한 후, Softmax를 적용해 확률이 가장 높은 단어를 예측함.
- 이를 수식으로 나타내면 아래와 같다.

- 온도(Temperature)는 Softmax Regression의 각 다음 토큰이 샘플링시에 뽑힐 확률을 뾰족하게 만들어 주거나 평평하게 만들어준다.
- 온도(Temperature) 값이 작을 경우 → 가장 확률값이 높은 토큰의 예측 확률이 증폭된다. → 가장 그럴듯한 토큰이 뽑힐 확률이 높아진다.
- 온도(Temperature) 값이 클 경우 → 모든 토큰의 확률값이 평평해진다. → 더욱 다양성 있는 텍스트가 생성될 확률이 높아진다.
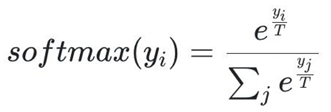
2️⃣ 온도(Temperature) 변화에 따른 다음 토큰 예측 확률의 변화
[링크] What is Temperature in NLP?



728x90
'AI & 딥러닝' 카테고리의 다른 글
| 불균형 데이터의 Resampling 전략 (0) | 2025.05.20 |
|---|---|
| OCR AI 자동맵핑 알고리즘 (Google Vision API, tkinter) (2) | 2025.05.20 |
| LLM 용어 정리 - 창발 능력(Emergent Abilites) (0) | 2025.02.26 |
| LLM 용어 정리 - In-context learning (1) | 2025.02.26 |
| LLM 용어 정리 - 토크나이징 (0) | 2025.02.26 |