
728x90
창발 능력(Emergent Abilites)
1️⃣ Emergent Abilities Paper
Emergent Abilities of Large Language Models (2022)
2️⃣ Overview

- Emergent abilities of large language models의 핵심 idea
- 큰 LLM 모델 학습 과정에서 특정 임계치를 넘으면 기존의 작은 LLM 모델에서 발생하지 않았던 새로운 능력이 발현됨.
3️⃣ Abstract
- 언어 모델의 확장은 다양한 하위 작업에서의 성능과 샘플 효율성을 예측 가능하게 향상시키는 것으로 나타났다.
- 그러나 이 논문에서는 큰 언어 모델(large language models)의 창발 능력(emergent abilities)라는 예측 불가능한 현상(unpredictable phenomenon)에 대해 논의한다.
- 만약 능력이 작은 모델에서는 나타나지 않지만 큰 모델에서 나타난다면, 그 능력을 창발 능력이라고 간주한다. 따라서 창발 능력(emergent abilites)은 작은 모델의 성능을 단순히 확장해서 추론하는 것만으로는 예측할 수 없다.
- 이러한 창발의 존재는 스케일을 더 키우는 것이 언어 모델의 능력을 추가로 확장할 수 있을지의 문제를 제기한다.
4️⃣ Introduction
- 언어 모델은 최근 몇 년 동안 자연어 처리(NLP)를 혁신시켰다.
- 언어 모델의 규모를 늘리는 것(예: 학습 계산, 모델 파라미터 등)이 다양한 하위 NLP 작업에서 더 나은 성능과 샘플 효율성으로 이어진다는 것은 이제 잘 알려져 있다.
- "모델 크기가 커질수록 성능이 어떻게 변하는지 예측할 수 있고, 크로스 엔트로피 손실도 단순한 선형적 변화가 아니라 7차 이상의 복잡한 곡선 형태로 변화한다는 것이 실험적으로 밝혀졌다." . - Kaplan 등, 2020; Hoffmann 등, 2022)
- "모델이 커질수록 대부분의 작업에서 성능이 좋아지지만, 일부 하위 작업에서는 크기와 성능이 반드시 비례하지 않는다. 그리고 어떤 작업이 그런 특성을 가질지 미리 예측하는 것도 어렵다." (Gangulli 등, 2022)
- 이 논문에서는 큰 언어 모델의 창발 능력(emergent abilities)라는 예측 불가능한 현상(unpredictable phonomena)에 대해 논의하겠다.
- 물리학, 생물학, 컴퓨터 과학과 같은 분야에서 창발(emergence)라는 개념은 오랫동안 논의되어 왔다.(Anderson, 1972; Hwang 등, 2012; Forrest, 1990; Corradini & O'Connor, 2010; Harper & Lewis, 2012, 그 외 다수).
- 우리는 Nobel 상을 수상한 물리학자 Philip Anderson의 1972년 에세이 "More Is Different"를 기반으로 Steinhardt(2022)에서 언급한 창발(emergence)에 대한 일반적인 정의를 고려하겠다.(Anderson, 1972)
- "창발(Emergence)은 시스템의 양적 변화가 행동의 질적 변화로 이어질 때 발생한다는 것이다."
- 여기서 우리는 학습 계산과 모델 파라미터 수로 측정된 모델 규모와 관련하여 창발(emergence)을 탐구하겠다.
- 구체적으로, 큰 언어 모델의 창발 능력(emergent abilites)을 작은 규모의 모델에는 존재하지 않지만 큰 규모의 모델에는 존재하는 능력으로 정의한다.
- 따라서 그들은 작은 규모의 모델에서의 성능 향상을 단순히 확장해서 추론함으로써 예측될 수 없다.( §2).
- 우리는 이전의 연구에서 관찰된 발생 능력을 조사하며, 몇 번의 시도로 프롬프팅(few-shot prompting)( §3) 및 확장된 프롬프팅 전략(augmented prompting strategies)( §4)과 같은 설정에서 그것들을 분류한다.
- 창발은 왜 그러한 능력이 획득되었는지 및 더 많은 규모 확장이 추가적인 창발 능력으로 이어질지에 대한 미래 연구를 동기 부여하며, 이것을 우리는 이 분야에서 중요한 질문으로 강조한다.( §5)
5️⃣ Emergent Abilities Definition
- 넓은 개념으로서, 창발(emergence)은 종종 비공식적으로 사용되며 많은 다양한 방식으로 합리적으로 해석될 수 있다. 이 논문에서는 큰 언어 모델의 창발 능력에 대한 집중적인 정의를 고려하겠다.
"능력이 작은 모델에는 존재하지 않지만 큰 모델에 존재한다면, 그 능력은 창발(emergent)하는 것으로 간주된다."
- 창발 능력(Emergent abilities)은 작은 규모의 모델에서의 확장 법칙(즉, 일관된 성능 향상)을 *외삽함으로써 직접 예측되지 않았을 것이다. (외삽, Extrapolation: 이미 주어진 데이터 범위를 넘어선 값들을 예측하는 방법, 알고 있는 데이터 바깥의 값들을 추정하는 과정)
- 규모 곡선(x축: 모델 규모, y축: 성능)을 통해 시각화할 때 창발 능력은 명확한 패턴을 보인다.
- 특정한 중요한 규모 임계값이 도달될 때까지 성능은 거의 무작위에 가깝다, 그 후에는 성능이 훨씬 높게 증가한다.
- 이러한 질적 변화는 또한 위상전이(phase transition)로도 알려져 있다.
- 작은 규모의 시스템을 조사함으로써 예견되지 않았던 전반적인 행동의 극적인 변화이다.(Huberman & Hogg, 1987)
- 창발적인 변화(새로운 능력의 출현)는 위상전이처럼 임계점을 넘었을 때 갑자기 발생할 수 있다. 처음에는 보이지 않던 극적인 변화가 작은 시스템을 분석함으로써 관찰될 수도 있다.
- 오늘날의 언어 모델은 주로 세 가지 요소를 따라 확장되었다: 계산량, 모델 파라미터의 수, 그리고 학습 데이터셋의 크기(Kaplan 등, 2020; Hoffmann 등, 2022).
- 이 논문에서는 각 모델의 학습 계산이 FLOPs(Floating Point Operations, 부동소수점 연산량)에서 x축으로 측정되는 다양한 모델의 성능을 플로팅하여 확장 곡선을 분석하겠다(Hoffmann 등, 2022).
- FLOPs는 컴퓨터가 수행하는 연산량(계산량)을 측정하는 단위
- FLOPs가 클수록 더 많은 계산을 수행한 모델이라는 뜻
- 이 논문에서 모델의 계산량(FLOPs)과 성능을 그래프로 그려서 모델 크기에 따라 성능이 어떻게 변하는지 분석하겠다.
- 더 많은 계산으로 훈련된 언어 모델은 일반적으로 더 많은 파라미터를 가지기 때문에, 우리는 추가적으로 모델 파라미터의 수를 x축으로 하는 플롯을 부록D에서 보여준다.(Figure 11 및 Figure 12, 그리고 Figure 4 및 Figure 10참조).
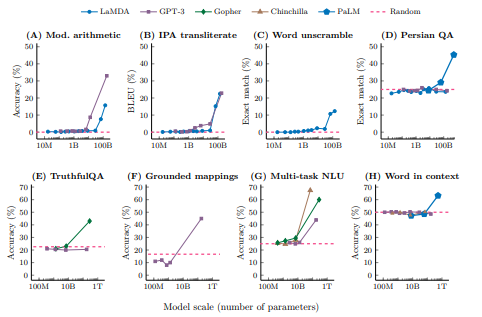


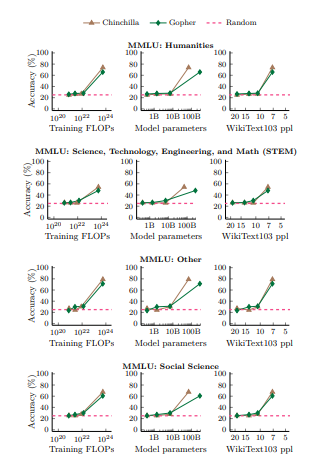
- 학습 FLOPs 또는 모델 파라미터를 x축으로 사용하면 대부분의 밀집된 Transformer 언어 모델 계열이 모델 파라미터와 거의 비례하여 학습 계산을 확장했기 때문에 비슷한 모양의 곡선이 생성된다.(Kaplan 등, 2020).
- 능력이 처음으로 발생한다고 관찰되는 규모는 여러 요소에 따라 달라지며, 그 능력의 불변하는 속성이 아니다.
- 새로운 능력이 처음 등장하는 모델 크기는 고정된 것이 아니라, 데이터와 학습 방식 등 여러 요소에 따라 달라질 수 있다.
- 예를 들면, 높은 품질의 데이터로 훈련된 모델의 경우 더 적은 학습 계산 또는 더 적은 모델 파라미터로 발생할 수 있다. 반대로, 발생 능력은 또한 데이터의 양, 품질, 또는 모델 내의 파라미터 수에 제한되지 않는 것과 같은 다른 요소에도 중요하게 의존한다.
- 데이터가 좋으면 모델이 작아도(파라미터가 적어도) 강력한 성능을 발휘할 수 있다.
- 단순히 데이터를 늘리거나 모델 크기를 키운다고 해서 반드시 원하는 능력이 생긴다는 보장은 없다.
- 오늘날의 언어 모델은 아마도 최적으로 훈련되지 않았을 것이다.(Hoffmann 등, 2022), 그리고 우리가 모델을 어떻게 가장 잘 훈련할 것인지에 대한 이해는 시간이 지남에 따라 발전할 것이다.
- 이 논문에서의 목표는 창발 능력을 관찰하기 위해 특정 규모가 필요하다는 것을 특성화하거나 주장하는 것이 아니다. 대신 우리는 이전 연구에서의 창발 행동의 예를 논의하려고 한다.
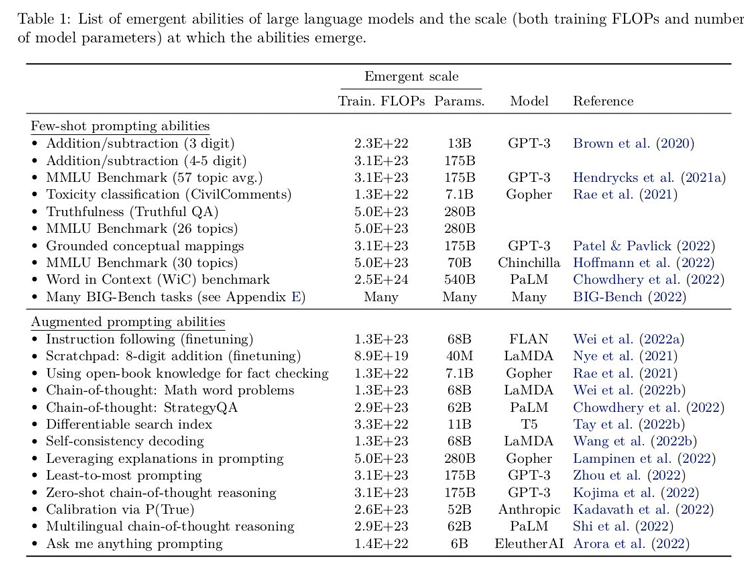
6️⃣ Few-Shot Prompted Tasks
- 우리는 먼저 GPT-3(Brwon 등, 2020)에 의해 널리 알려진 프롬프팅 패러다임에서의 발생 능력을 논의한다.
- 프롬프팅에서는 사전 훈련된 언어 모델에 작업의 프롬프트(예: 자연어 지시)가 주어지며, 추가적인 훈련이나 그래디언트 업데이트 없이 응답을 완료한다.
- Gradient Update: 모델이 더 나은 예측을 하도록 가중치(파라미터)를 조정하는 과정
- Brown 등(2020)은 모델의 컨텍스트(입력)에 몇 가지 입력-출력 예제를 포함시키는 것을 제안했는데, 이는 모델에게 보이지 않는 추론 시간 예제에 대한 작업을 수행하도록 요청하기 전에 서두로 사용되니다.
- 예제 프롬프트는 Figure 1에 표시되어 있다. 모델이 특정 규모에 도달할 때까지 무작위 성능을 가지고 있고, 이후 성능이 훨씬 높아질 때, 몇 번의 프롬프팅을 통해 작업을 수행하는 능력은 발생하는 것으로 간주된다.

- Figure 2는 다양한 연구에서 다섯 가지 언어 모델 계열에 걸쳐 나타나는 여덟 가지 발생 능력을 보여준다.
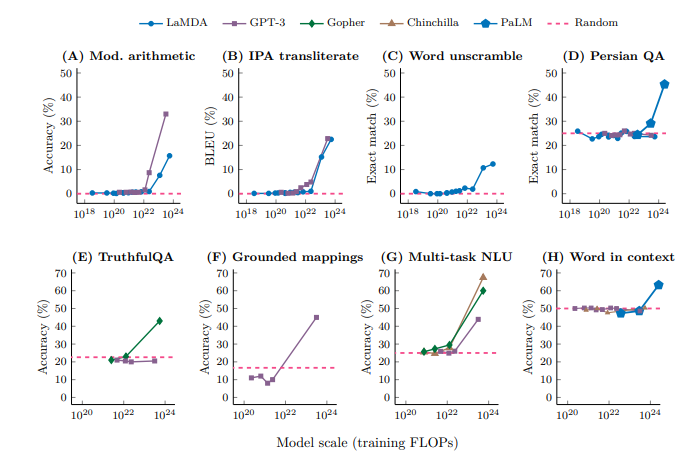
7️⃣ Augmented Prompting Strategies
- Chain-of-Thought Prompting과 같은 Augmented Prompting 세팅에서 창발 능력(Emergent Abilites)
- Chain-of-Thought Prompting: 복잡한 문제를 해결할 때, 한 번에 답을 요구하느 것이 아니라, 단계별로 논리를 전개하도록 프롬프트를 작성하는 방식
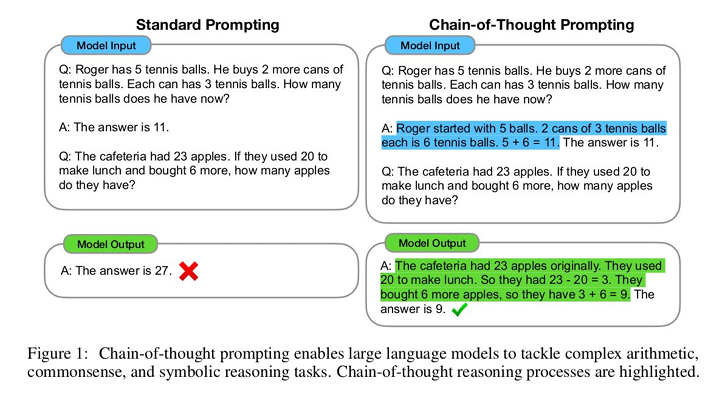
8️⃣ Chain-of-Thought Prompting Results
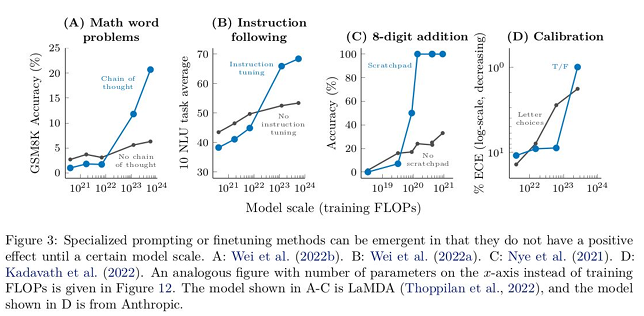
9️⃣ Few-shot, Augmented, Chain-of-Thought 에서 Emergent-Abilities 가 발생하는 파라미터 사이즈 모델 별 비교
🔟 Conclusion
- 우리는 언어 모델의 창발 능력(emergent abilites)에 대해 논의했으며, 의미 있는 성능은 지금까지 특정 계산 규모에서만 관찰되었다.
- 창발 능력은 다양한 언어 모델, 작업 유형 및 실험 시나리오에 걸쳐 나타날 수 있다. 이러한 능력은 언어 모델의 규모를 확장하는 결과로 최근에 발견되었으며, 그것들이 어떻게 발생하는지와 더 많은 규모 확장이 추가적인 창발 능력을 가능하게 할지에 대한 질문은 NLP분야의 중요한 미래 연구 방향으로 보인다.
- 보다 광범위한 영향에 대한 서술(Broader Impact Statement). 이 논문에서는 새로운 방법이나 모델을 제안하지 않고 기존의 문헌에서의 결과를 조사했다. ( §5)에서 논의한 것처럼, 창발 능력은 여러 방면에서 예측할 수 없으며, 창발 위험( §5.4)을 포함한다. 우리는 이러한 현상이 주의 깊게 연구될 필요가 있으며, 이 분야에 중요한 질문을 제기한다고 믿는다.
728x90
'AI & 딥러닝' 카테고리의 다른 글
| OCR AI 자동맵핑 알고리즘 (Google Vision API, tkinter) (2) | 2025.05.20 |
|---|---|
| LLM 용어 정리 - 온도(Temperature) (0) | 2025.02.26 |
| LLM 용어 정리 - In-context learning (1) | 2025.02.26 |
| LLM 용어 정리 - 토크나이징 (0) | 2025.02.26 |
| 기업별 대표 LLM 사용 및 비교해보기 ChatGPT, Bard, CLOVA X (0) | 2025.02.25 |